Data and postal address deduplication software
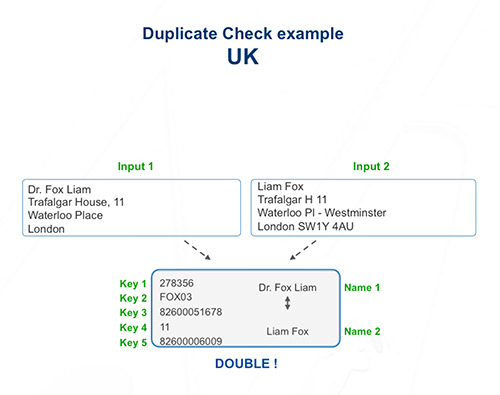
Data deduplication and postal address deduplication (duplicate check) involve identifying any certain or presumed duplicated addresses in the database, caused by inaccuracies or inconsistencies, and the duplicates can then be reduced to a single form.
Are there any duplicates in your database?
If you need to eliminate the duplicated data in your business database, or you need a tool to integrate with your application and check data input by highlighting any superfluous or duplicated input (as the record is already archived), then try EGON.
WHY DATA DEDUPLICATION?
Data quality needs all the aspects have to be correctly handled, and duplicated data are a problem for both man-software interaction and for unexpected expenses, for example, in the specific field of address deduplication, due to double mailings of advertising material or official notifications to the same company, which not only wastes money but also harms the company’s image.
When sending correspondence, the availability of a correct, complete, validated and duplicate free database is a sign of professionalism, which is why integrating an automatic validation software grants considerable benefits. If a number of databases need converging, deduplication can be applied to natural persons and legal entities, and exploits the “match-code” method, which permits: eliminating the duplicates, identifying families, enhancing internal data.
- Data correlation
- Integration of the registry data, records, addresses and archives
- Unification of data and documents about a single subject
- Management of a single position for the subject and assigning a PIN
- Management of duplicated data